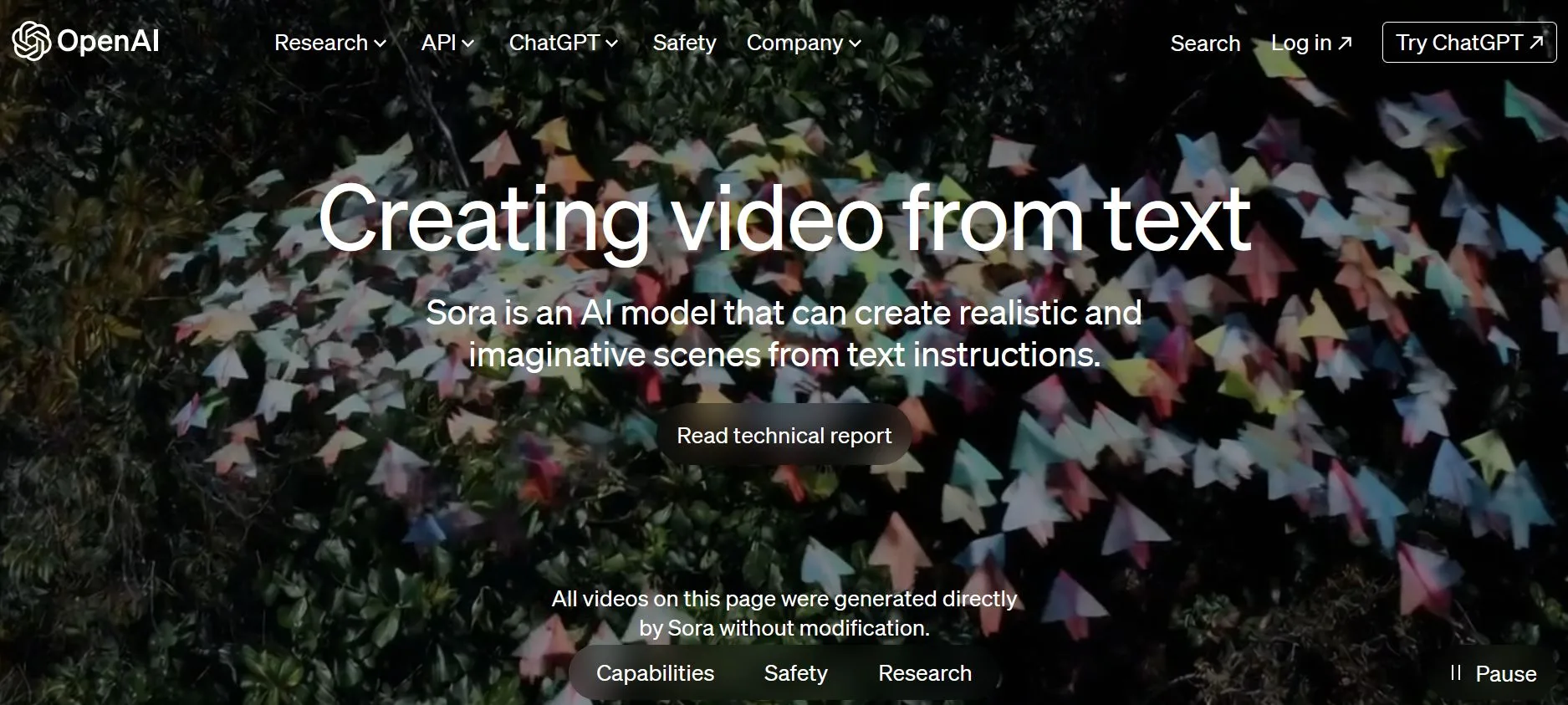
Sora 是一款新的 AI 模型,能夠根據文字指令創建逼真且富有想象力場景的影片,這可是相當受到矚目的發展。
OpenAI 這次發表了 AI 產影片模型 Sora 的研究成果,在該公開網頁上強調,頁面上的所有影片均由 Sora 直接生成,未經修改,夠直球對決。
OpenAI 指出,他們正在教導 AI 理解並模擬運動中的物理世界,目標是訓練出幫助人們解決需要實際世界互動的問題的模型。
這次的 Sora 我在想如果用日文來發音,就是天空的意思,代表 AI 之後的未來海闊天空嗎? XD 這個文字到視頻模型,可以生成長達一分鐘的影片,同時保持影像品質,以及對用戶下的提示詞之遵循,相信未來可以做出更長時間的影片,目前我們可以產很多段再來組合也行。不過對於其他文字產生影片的 AI 工具如Heygen、Pika等來說,這就是重大威脅了, OpenAI 的 Sora 很明顯地呈現效果更好。
Sora 現階段正評估潛在的危害或風險領域外,同時也讓全球部分視覺藝術家、設計師和電影製作人取得測試訪問權限,OpenAI 公司可藉此了解怎樣才能對全球業界是有幫助的,進而做出更改良過的文字產影片 AI 模型出來。
讓我們拭目以待,以下是 Open AI 這次發表的影片範例,確實很強大:
Introducing Sora, our text-to-video model.
Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions. https://t.co/7j2JN27M3W
Prompt: “Beautiful, snowy… pic.twitter.com/ruTEWn87vf
— OpenAI (@OpenAI) February 15, 2024
提示詞翻是可以是這樣: “Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes.”
Prompt: “A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. she wears a black leather jacket, a long red dress, and black boots, and carries a black purse. she wears sunglasses and red lipstick. she walks confidently and casually.… pic.twitter.com/cjIdgYFaWq
— OpenAI (@OpenAI) February 15, 2024
Prompt: “A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. she wears a black leather jacket, a long red dress, and black boots, and carries a black purse. she wears sunglasses and red lipstick. she walks confidently and casually.… pic.twitter.com/cjIdgYFaWq
— OpenAI (@OpenAI) February 15, 2024
根據 OpenAI 的技術檔案,從Sora 的訓練過程來看,Sora 實際上是一種擴展型變換器模型(diffusion transformer)。
Sora 與 DALL·E 3 模型相似,也採用了GPT技術,對使用者的提詞轉換成更詳細的指示,然後傳送給智慧模型去處理。
延伸閱讀:
Video generation models as world simulators