中國的 DeepSeek AI 模型日前非常熱門,包括 DeepSeek V3、DeepSeek R1 的釋出,其呈現的效果不輸美國幾家大手的 AI 模型,讓人好奇是怎樣做的,如果觀看他們的論文,大概可知一二,這種訓練方式後續也會各家來採用,來加快迭代的時間,以及提升模型的品質。DeepSeek 也能夠在本地端跑,然後雲端一堆可以測試的,而許多UI直接可以串它的API去用。預期未來滿多其他AI模型也會用新的訓練方法和流程去改善各自的產品。
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning 論文在這邊,可以好好看他們的寫法,這篇論文最大的貢獻,主要就是在 LLM 的訓練方法論上。
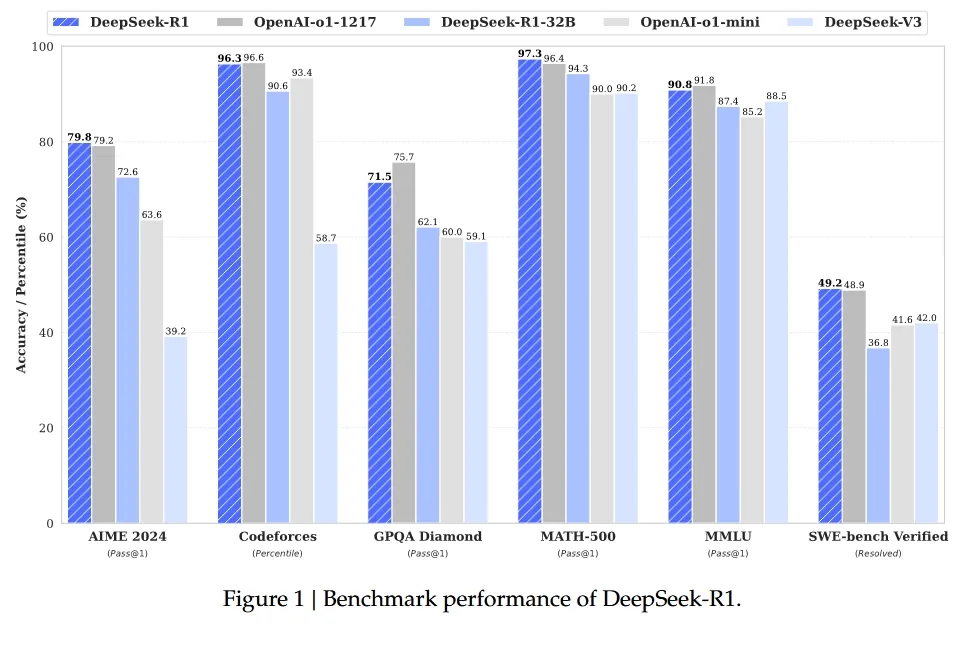
根據諸多報導和市場跡象顯示,DeepSeek 對外講的號稱是大廠十分之一的低成本訓練,其實重點只有在 V3 這個模型的後訓練中提到,實際上他們可能還是有數萬張 Nvidia H100之類的算力資源在支撐著 R1 的前期訓練和計算。從另一個角度來看,不論是怎樣的成本訓練降低,還是需要 Nvidia 高效能繪圖卡,以及相當的運算資源,這點在馬斯克他們 X.AI,透過相當數量的 Nvidia 顯卡,但改用不同的訓練方式,也能產出相當優秀的 X.AI 模型成果是異曲同工之妙。
DeepSeek 本身使用的基礎模型是Meta 的 llama 3,並使用 gpt4o 作為驗證器,我自己除了測試 DeepSeek 的雲端版本外,也把 DeepSeek 可在本地端跑的版本也下載到電腦中讓我的設備去跑,以及丟到 NAS 上去跑。我自己測試的結果,是很明顯如果單單要讓處理器去運算我提問的問題,系統要跑非常久的時間,當你把 layer 指定給 GPU 的部分納入,速度才會快上一點。
在自己電腦上跑的好處,是可自由切換不同版本LLM模型來測。
我目前覺得LLAMA 3.X、Mistral、Qwen都相當好用,DeepSeek則較侷限在某些範圍有不錯效果,當然可能因我在本機跑蒸餾版本8B的緣故,因此市場上目前熱門的阿里巴巴的千問,拉回來跑會覺得更有意思。
至於微軟的小模型PHI-4,許多任務效果不錯。當然不要忘了還有Google的Gemma小模型,反正以上主要下7B、8B、14B等小版本來跑即可。
現階段在雲端跑的 DeepSeek 就滿多可以測試看看效果的,而蒸餾過的縮小版模型,我覺得進一步來說,再繼續改善後,在中國市場自己品牌的智慧型手機或許能夠納入,跑滿多日常生活中會用到的情境應用輔助。
DeepSeek 資料集的部分,我觀察到它用了相當多中國市場在地的網路文本來訓練,不論是網路小說啦,論壇資料、新聞資料等等,這讓 DeepSeek 在進行創作上,會有不錯的效果,畢竟是有一堆資料拿來跑。
eepSeek R1 目前一共有下列幾個版本的開源釋出:
1.5b 7b 8b 14b 32b 70b 671b
對一般人來說,用到7b、8b、14b 已經算極限了,更大的32b、70b,特別是 70b 這個版本就很強了,你需要記憶體夠大的伺服器和Vram夠大的Nvidia顯示卡,比方說好幾十GB VRAM的高規 AI 推論用 GPU,也是得花不少成本。
671b 參數的最大版本,大概只能在雲端跑,一般人或中小公司絕對沒有這種能跑這等級規模AI的設備,也不容易部署。
至於被各國陸續抵制禁用的是雲端版本,那個有他們官方的任務先不管,該平台版本應該是比671b參數版本更龐大的內容,這個他們應該不會特別講太多,算商業秘密了。可以用的就是放在Github、HF、Ollama上的這些公開模型,蒸餾後的中小型版本,就已經滿夠用了。
我認為較小型版本的 AI 模型,拿來給手機、工業電腦裝置去跑會有市場,中國、印度等國應該都會走這條應用路線,超大的平台則是看大家進度囉。
而微軟phi-4的效果真的很優秀,推薦使用,只要你的顯示卡VRAM夠多如16GB,拿它來跑很多事情會很有幫助,推論速度滿快的。14b參數的版本能力也夠用。
按照市場上謠傳的中國團隊其實透過新加坡買了一堆 Nvidia 顯卡資源,也是有可能的,因為這個號稱低成本訓練的模型,從已知資料來看,應該只有後面的訓練是這樣用的,實際上,進一步來看,打造出 DeepSeek 的中國廠商幻方,那個五百多萬美元的低成本訓練,是在 DeepSeek v3技術文件上提到的,且是真的僅包括DeepSeek-V3的正式訓練,不包括Pre Training、前期研究、演算法、資料集相關的成本。
從架構上來看,R1 和其他 AI 模型相比,真的沒有非常特別的地方,能讓人津津樂道的,是它最大的改變是整個訓練的流程是新的,而這種新的流程的改變,就能夠有更好的結果,而依據這樣的案例來看,擁有高算力的其他 AI 大手公司,也能夠藉由這個方法,以及這個方法的改良,去打造出更優質的 AI 模型出來。
由於 DeepSeek 目前是開放原始碼,和之前 Meta 釋出的 llama 都是開放原始碼,所以可以期待之後更多人參考這部分的進展。
對於市場上其他 AI 公司、Nvidia 晶片廠商來說,AI 的算力資源確實還是重點,而包括我之前提到 Google 在 2025 年新的 AI 運算場、Meta、OpenAI、X.AI與微軟等廠商繼續在算力方面的投資,可預期 2025 下半年將會有相當精彩的新模型與更好的應用能誕生,而中國的 AI 市場發展,是否會受到算力的影響,也是未來觀察的重點。