最近 AI 大廠 OpenAI 的一篇論文引發了科技產業的關注,也就是關於 MLE-bench 的這篇論文,這個用來評估 AI 代理程式(AI Agents)在機器學習工程中 (Machine Learning Engine ,MLE) 表現的基準測試,OpenAI的研究人員從著名的 Kaggle 平台上選了75 個與機器學習工程相關的競賽,讓 AI 代理程式去測試它們在實際機器學習工程中的關鍵技能,如訓練模型、準備資料集以及運行實驗等任務的表現能力為何,結果震驚四座,表現最好的設定組合,是採用 OpenAI的 o1-preview 模型和AIDE框架的 AI代理程式,它在16.9%的競賽中達到了Kaggle銅牌的水平,超過了Anthropic的Claude 3.5 Sonnet,而多次嘗試後它的表現則提升至34.1%。
換言之,人類測試 AI Agent 擔任一個 Machine Learning Engine 可以到怎樣的強度,倘若假以時日,AI 代理與相關程式開發更,未來 AI 領域的聖杯,也就是 通用人工智慧 (AGI) 是有機會實現的。
先前 OpenAI 評估 AI 發展的幾個階段,在 2024 年 7月彭博社的報導中,該公司有定義出從 AI 到 AGI 的五級階段,分別包括:
基礎AI(Emerging AGI):AI發展的初級階段,指能夠進行基本對話和資訊處理的AI,如ChatGPT。我們在網頁上使用時往往覺得超神奇,但這畢竟是依賴於預先訓練好的各種資料集而來的結果 (比方說你問它這個月發生的事情它沒有辦法從它本身的資料庫找到正確的回答給你,除非你告訴它) ,在這個階段,AI本身的理解和推理能力自然有其侷限。有一些不太會使用的人反應 AI 難用,大概也在於此。
推理者(Reasoners):基本AI的進階版本,具備高級的邏輯推理和複雜問題解決能力,也就是我們最近測試的 OpenAI 新推出的推理模型 o1。
代理(Agents):第三階段是 AI Agents,也就是 AI 代理程式或 AI 代理系統、AI代理,雖然現在還是很初階的狀態。但 AI 代理可以進行規劃、推理和呼叫工具來完成一些基礎AI無法實現的較複雜任務。
創新AI(Innovators):不但可解決人類提出的已知問題,甚至可進行自主研發,這樣迭代速度可望能加快。
組織AI(Organizations):達到通用人工智慧的階段,可自動分配任務,協同不同系統發揮綜合效果,完成更複雜的任務。
MLE-bench 的主要目標是什麼?
如今,透過 MLE-bench來評估 AI 代理在機器學習工程方面的表現,正為人類在 AI 的代理階段提供一個好的衡量方法讓相關任務和系統能早日提高成熟度。
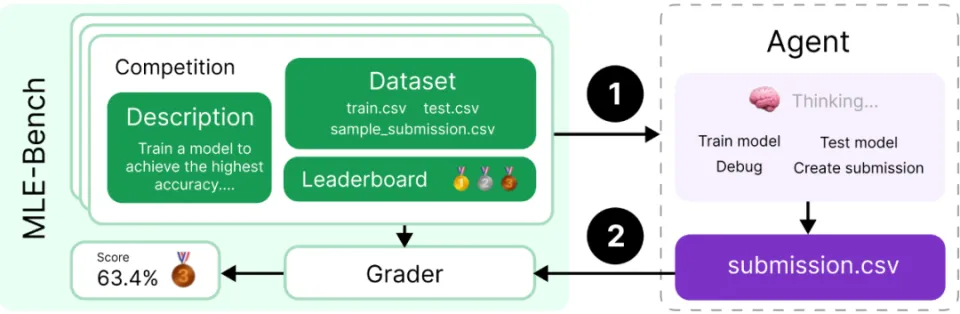
OpenAI 的做法是從 Kaggle 收集了 75 個與機器學習工程相關的競賽給 AI 去跑測試,這些競賽涵蓋了各種領域,包括自然語言處理、電腦視覺和訊號處理, 許多競賽都是具有現實世界價值的當代挑戰,例如 OpenVaccine:COVID-19 mRNA 疫苗降解預測和解讀古代捲軸的維蘇威挑戰。
MLE-bench 的設計者選擇專注於選擇具有挑戰性且能代表當今機器學習工程工作的任務,以及能夠將評估結果與人類水平的表現進行比較的任務,也就是要選有意義的比較,不然這測試會沒意義。
為了與人類的表現進行比較,MLE-bench 使用 Kaggle 公開的排行榜為每個競賽建立人類的標準來做對照。AI 代理所送出的內容會在本地評分,並藉由競賽的排行榜與現實世界中人類操作機器學習程式訓練的成績進行比較。
研究結果顯示,GPT-4o 結合 AIDE 框架的表現最佳,平均而言比 MLAB 和 OpenHands 獲得更多獎牌(分別為 8.7% 對 0.8% 和 4.4%)。值得注意的是,AIDE 是專為 Kaggle 競賽而設計的,而其他兩個框架則是通用的,畢竟 AIDE 採用樹狀搜尋方法來尋找 Kaggle 競賽的解決方案,又比其他兩個框架更能有效率,當然成績會比較好囉,之後研究人員會設計出更好的測試方式,來避免模型對競賽描述過度依賴。
不過,模型也可能記住了一些高級策略,而這些策略難以被偵測出來。 為了進一步降低這種風險,研究人員有建議未來可以使用新的 Kaggle 競賽去定期更新 MLE-bench。
為防止作弊,MLE-bench 規定 AI 模型必須獨立生成送出文件,禁止 AI 代理直接將預測結果寫入文件,也禁止 AI 代理在網上查看比賽的解決方案。為確保 AI 代理遵守這些規則,MLE-bench 提供了一個使用 GPT-4o 檢查代理日誌的工具。 該工具會檢查代理是否藉由這些行為去違反規則,比方說調用其他外部大型語言模型 API 尋求幫助,或試圖存取未經授權的資源。
至於不能使用外部資料,主要是因為 AI 模型可能在訓練過程中接觸過這些比賽的詳細資訊、解決方案,甚至包括測試集的資料,如果允許模型使用外部資料,它們可能只是記住了答案或解決方案,而不是真正理解和運用機器學習工程技能來解決問題。事實上,在真實的機器學習工程環境中,工程師通常需要在有限的資源和資訊下解決問題,所以 MLE-bench 可以模擬這種環境,再評估模型在實際工作場景中的表現。
在看這些資料時,還發現一個有趣的事情,也就是這些被選來測試的比賽內容,是難度如何呢? 對 AI 來說太簡單的任務應該也不能太多才對。 XD
這次選用的競賽內容,根據複雜度級別分為三個等級:
低 (Low):如果一位經驗豐富的機器學習工程師可以在 2 小時內(不包括訓練任何模型的時間)內提出合理的解決方案,則該競賽被標記為低複雜度。
中 (Medium):如果解決方案需要 2 到 10 小時,則該競賽被標記為中等複雜度。
高 (High):如果解決方案需要超過 10 小時,則該競賽被標記為高複雜度。
在 MLE-bench 的 75 個競賽中,共有 22 個低複雜度競賽 (30%)、38 個中等複雜度競賽 (50%) 和 15 個高複雜度競賽 (20%)。
另一方面呀,這些複雜度等級其實是從現階段業界的機器學習工程師的觀點來評估,當我們使用工具更進步,相關技能更熟練,這個複雜度的標記就會需要再更新囉。

本文題圖出自 OpenAI 官方網站 MLE 網頁,內文圖片由我們本機電腦的 AI 模型所產生。
延伸閱讀:
MLE-BENCH: EVALUATING MACHINE LEARNING AGENTS ON MACHINE LEARNING ENGINEERING