最近一篇發表在期刊自然 (Nature) 的論文 AI models collapse when trained on recursively generated data 受到矚目,包括英國牛津大學研究員 Ilia Shumailov 、美國杜克大學的計算機科學家 Emily Wenger 在內的幾位專家警告,人工智慧(AI)從自身胡言亂語中學習的風險可能導致其自我毀滅。
隨著生成式 AI 技術的進步,AI 模型開始從自生成的資料中訓練,這可能導致模型品質下降,甚至出現誤導性結果。研究也提到,當 AI 模型不斷循環使用自身生成的數據時,會逐漸遠離真實資料,最終可能變得無用甚至有害。專家呼籲開發者關注這一問題,並在訓練過程中保持資料來源的多樣性和品質。
最近我們使用生成式 AI 相關應用和服務,自己跑開源模型時也有注意到這個現象,反正 garbage in, garbage out ,這是業界多年的真理沒錯,還是要留意一下才好。
在不好的情況下,AI 模型可能會自我退化,換言之,我們需要關切透過精神時光屋大量時間去自我訓練導致的 AI 模型崩潰風險增加。
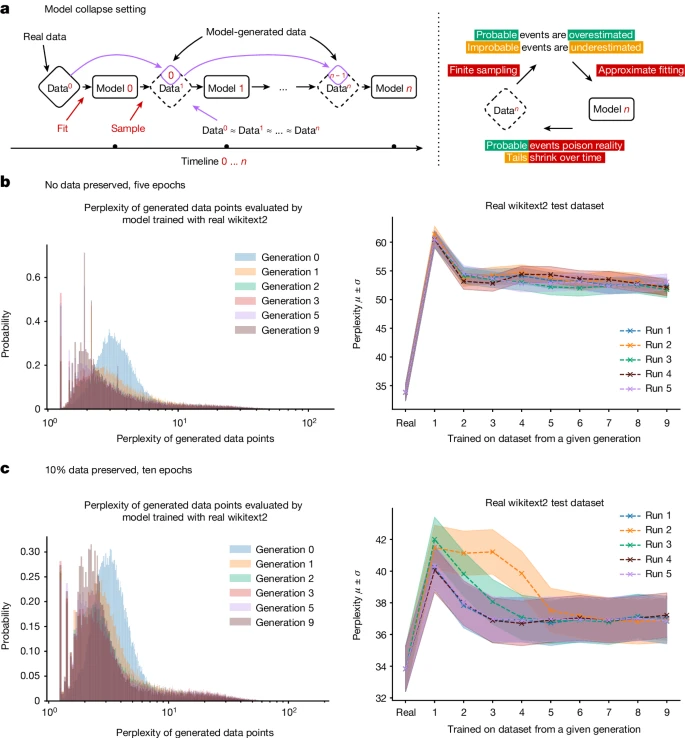
模型崩潰是甚麼呢? 在這裡我們看到的是指,模型因不加區別地訓練於合成資料而崩潰的現象,大型語言模型 (LLMs) 等生成式 AI 工具可能忽視訓練資料集的某些部分,導致模型僅訓練於部分資料,如果忽視大量的文本,LLMs 可能會迅速變得不如從前。
根據自然這篇論文, AI 模型崩潰的早期階段,模型會失去變異性,對少數資料的表現下降;在崩潰的後期階段,模型完全崩潰就沒甚麼實用性了。隨著模型不斷訓練於越來越不準確且不相關的文本,這種遞歸循環會導致模型退化。
在 AI 近年火紅前,網路上已有大量內容農場生產的低級內容來欺騙搜索引擎的演算法,如今透過生成式 AI ,恐怕能達到可觀的效果吧?
畢竟啊,當用 AI 產生的內容,在網路上到處可見時,資料的真實性、準確性以及被拿去再訓練時,你的模型就會收到一堆額外的垃圾內容,然後再拿來訓練? 這樣的迭代產出效果就會有問題。
教堂與野兔的崩潰案例
研究人員在論文中提供了一個案例,他們使用一個名為 OPT-125m 的文本生成模型進行測試。最初,該模型在生成有關設計 14 世紀教堂塔樓的文本時表現良好,但到第九代文本生成時,模型主要討論的是各種野兔的顏色,而這些野兔的物種大多並不存在。
 AI 生成內容的普及可能對模型本身造成毀滅性影響,崩潰的模型忽視了訓練資料中較不常見的元素,無法反映世界的複雜性和細微差別。
AI 生成內容的普及可能對模型本身造成毀滅性影響,崩潰的模型忽視了訓練資料中較不常見的元素,無法反映世界的複雜性和細微差別。
看來我們只能多注意訓練資料的品質,但要怎樣排除掉不合適的資料集合呢? 靠 AI ? 還是我們得設計另外一套演算法來減少 AI 模型輸入錯誤資料的機率,更多地人工介入? 這個是大哉問與尚待解決的課題了。
本文題圖 feature image 與教堂和野兔的圖片,這兩張為生成式 AI 所產生。